Parser Combinator Experiments in Rust - Part 2: Error handling
I published the previous blog post on reddit and got some interesting feedback from that. I also talked a bit to the creators of Nom and Combine which finally helped me make a decision regarding manual threading-of-state vs boxed closures.
I have decided to proceed with the manual threading-of-state since it is performing a lot better,
is just as modular (boxing of parsers can be done if you need some dynamic dispatch) and it is not
too different from the boxed-closure version. If Rust improves enough for unboxed closure returns
I might be able to completely update the parser to use closures instead of manual passing of state
in a X.0 breaking update without making it difficult to upgrade.
This will be a pretty long post since it deals with quite a lot of the different things which can be done in relation to error handling.
Comparison with Combine
Since people wanted me to include more parser-generators in my simple benchmark I have had some
help from the creator of Combine to produce two versions of the benchmark for it. The first version
is using the stock version of Combine, 1.0.0-beta.3, which does not support zero-copy parsing.
The second version is using the the unfinished 1.0.0 version which has support for zero-copy
parsing as well as other improvements.
This time I ordered them from fastest to slowest on the 204 MB file:
| Parser | Time, 21 kB | Time, 2 MB | Time, 204 MB |
|---|---|---|---|
| C http-parser | 0.003 s | 0.009 s | 0.62 s |
| Manual | 0.003 s | 0.015 s | 1.19 s |
| Nom | 0.003 s | 0.018 s | 1.42 s |
| Attoparsec | 0.004 s | 0.021 s | 1.45 s |
| Combine-pre | 0.004 s | 0.024 s | 2.15 s |
| Boxed | 0.004 s | 0.041 s | 3.75 s |
| Combine-beta | 0.004 s | 0.077 s | 7.04 s |
| Parsec1 | 0.009 s | 0.490 s | 47.75 s |
1: Uses the exact same parser-code as the Attoparsec benchmark.
The difference of not having to allocate any Vec<u8> instances is quite huge which can clearly
be seen in the performance of Combine-pre vs Combine-beta. In addition to this Combine-pre has
much better support for parsing &[u8] which reduces the noise in the parser greatly.
The above test is still using the code from the previous blog-post, I will be listing the performance of the improved/rewritten parser further down.
Tradeoffs
Now that we have looked at the numbers again a bit I will have to go through the limitations my parser will have. Making a completely generic parser and then get it to perform well is pretty difficult, and to make one which is both performing well and is easy to use is even harder, so I have to limit it a bit.
Currently I have settled for the following tradeoffs:
- Only works on slices, does not accept iterators as a data-source.
- The data in the source-slice must be
Copy, this allows for simpler smaller parsers and cuts out a lot of the noise from pointer-dereferencing when matching data. - Need to restart parsing whenever incomplete inputs are encountered, this might also mean that data needs to be moved/copied in the source-buffer if all data is not immediately available.
- Errors are bound to the current input-source, forcing users to deal with them before restarting parse (or saving some kind of copy before resuming).
I am not 100% certain about any of these, but it seems to be allowing for a pretty fast and flexible parser. If larger inputs need to be consumed the parser-combinator could be demoted to a lexer, to make it cheaper and more convenient to just restart the parser on incomplete input and keep some kind of datastructure persistent between invocations of it.
Error handling
Error handling is something people also seemed to be interested in, what different approaches can be made and how it impacts both performance and readability of error messages. Seeing as I have already made the tradeoff which requires an immutable underlying buffer for every invocation into the parsers I do not have to consider the situation where I have to duplicate parts of the input stream to produce a readable error message.
Another simplification I have decided on is to not let bind [automatically backtrack on error] (https://github.com/m4rw3r/rust_parser_experiments/blob/f64d0cc317c5d850987b83f206191eeed1e9bb68/src/lib.rs#L226)
for the next version. Instead it is up to the appropriate combinators to hold a reference to the
original slice and backtrack if needed. This should simplify some logic and hopefully enable LLVM
to optimize it a bit better. For most of the parsers and combinators the original input position is
completely useless seeing as there is nothing to be done once an error has occurred.
One additional optimization regarding errors is that we can omit the actual unexpected token or
state since we always point at the error with the slice in Parser. In the previous version we
did not guarantee that the slice actually survived when yielding the error. This means that we can
now have an even simpler Error without any data at all!
Further, we can optimize many1 to actually not need to stack or wrap errors — instead it just
needs to pass through the existing error — because of the following equivalence:
// Haskell
many1 p = p >>= \x -> many p >>= \xs -> return x:xs
// Rust parser
many1(p) = bind(p(m), |m, x|
bind(many(m, p), |m, xs|
ret(m, xs.insert(0, x))))
This is of course a simplification since the result of many and many1 are not always
vectors. And it still requires some modifications to the internal Iterator used by many
and many1 so that it will actually propagate the error instead of throwing it away, as it
did in the previous version.
So we will have the following two simplified Error types to compare:
struct Error;
enum Error<I>
where I: Copy {
Expected(I),
Unexpected,
String(Vec<I>)
}
And then the common Parser implementation:
enum State<'a, I, T, E>
where I: 'a {
Item(&'a [I], T)
Error(&'a [I], E),
// Reporting incomplete input does not need to actually return the slice
Incomplete(usize),
}
// Newtype wrapper to avoid exposing the internal state
pub struct Parser<'a, I, T, E>(State<'a, I, T, E>)
where I: 'a;
Custom errors
Of course, the default errors are still not good enough for a real application if the output ever reaches the end-user. Just mentioning something like “Expected ‘foo’ at ‘baz bar’” is not good enough and application- (or library-) specific error types are required to properly describe parse-errors.
Currently bind is generic over the error passed, automatically converting the error from the
first parameter to the error-type of the second parameter using From::from. This should enable
some flexibility in handling errors, but I am not certain this is enough.
This works well when bind is used like this since the first error will be converted to the error
type of my_parser:
mdo!{input,
char(b':');
data = my_parser();
ret data;
};
It does not work so well when it is done in reverse however, as that will attempt to convert from
the potentially user-defined error-type from my_parser into the Error type of the parser
library:
mdo!{input,
data = my_parser();
char(b'\n');
ret data
};
Another problem with this is inference, since the second parameter does not always have an error
AND a value specified for its type (eg. it is common to just end with a ret or err). This
will force the use of a few type-annotations when parsers are added and used inline in a function.
It will not be a problem if the parser is wrapped in a function however.
The map_err approach which std::result::Result
uses is something which could solve this problem. Allowing errors to be converted to the desired
type right after the parse-operation will solve the problem illustrated in the second example
above, it will enable the user to convert the error of char to the appropriate error before
the ret.
Enabling constructions like this will solve the issue:
mdo!{input,
data = my_parser();
char(b'\n').map_err(MyError::ParseError);
ret data
};
This exact syntax does not play nice with the mdo! macro at the moment, but it is something I
am working on.
Type inference
There is still a minor annoyance with this construction for error handling, the type inference for
the error type is not as simple as it could be. In current stable Rust (1.2) given that f
does not have any specified error type then bind(m, f) will cause rustc to fail to infer
the type of bind since the returned error type is the error type from f.
This can be solved by adding a default type parameter
for the error of f so that it will default to the existing error type, this will cause
rustc to use that type if it cannot infer a type for the error type of f. Sadly it is just
partially usable at the moment in stable rust; stable rust accepts the syntax of the default type
parameter but does not use it as a fallback in case the inference fails.
To be able to use the default type as a fallback nightly rust must be used and the crates which
want to enable the fallback in the code they use must enable the feature gate
default_type_parameter_fallback. This will cause rustc to use the fallback for all code
in the crate, this includes code from other libraries used in the crate (eg. if bind is used
and inference is wanted for it, it is the crate which performs the call to bind which needs the
feature enabled, not the library where bind is defined). There is a
tracking issue for the fallback, and it seems
like it is just waiting for some more testing in the wild before it is enabled by default.
Since the default type parameters do not actually affect stable at all it is a harmles addition to the generic types:
pub fn bind<'a, I, T, E, F, U, V = E>(m: Parser<'a, I, T, E>, f: F)
-> Parser<'a, I, U, V>
where V: From<E>,
F: FnOnce(Input<'a, I>, T) -> Parser<'a, I, U, V>;
Note V = E above.
In the future default type parameter fallback can be used to simplify error handling around parsers
which do not return any error (eg. any). Currently they “return” Error<I> to be consistent
with the other parsers which forces the user to handle the error case even though it is not at all
necessary, since the type could just be free, but the alternative is to force the users on stable
Rust to annotate the error-type every time any of these functions are used. By using the generic
E = Error<I> instead once default type parameter fallback has landed it will be easier for the
user to use these parsers while it does not break any existing code.
Comparing the two
To avoid having to copy-paste almost every parser I conditionally compile a private internal
module which contains the Error type definition as well as constructors for the errors.
This is done using the --features flag of Cargo. By default the parser will include the
verbose errors, but --no-default-features can be used to make errors carry no data (could
be useful for some applications if the extra data in the error messages is not needed and the
performance gain is justified).
The simple version of the module only contains noops for managing the data, returning just the
error values. The more complex version contains some minor logic to populate the Error data.
Inlining
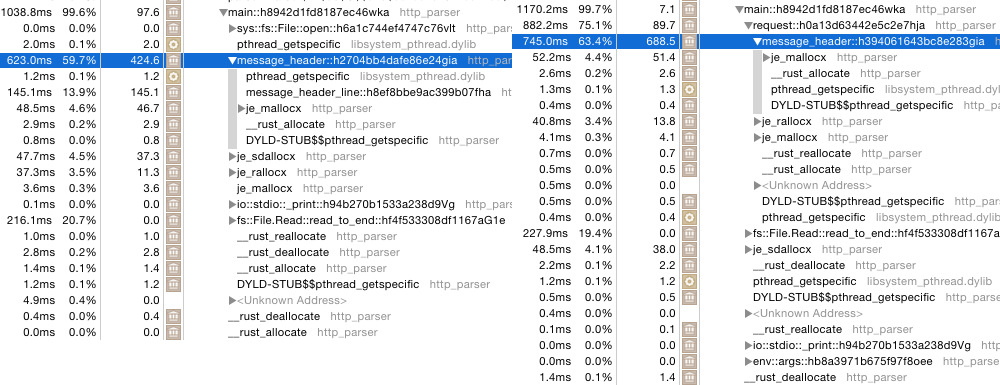
Every time changed something I timed the run on the 200 MB file to see if the run-time
changed, and if the different error handling approaches had much of an impact on performance.
Pretty consistently the noop error was about 10% faster for most of the changes I did, but when
I tried to simplify the private iter::Iter I ran into a problem; suddenly the larger error
enum performed better than the empty one.
It turns out that LLVM is suddenly inlining different functions in the parser code; for the
faster version it inlines request and all its callees except for message_header (which
in turn has everything inlined except for message_header_line). In the slower version
request is NOT inlined nor is message_header but it inlines message_header_line
instead.
Clearly I need some way to make the inlining equivalent for both tests.
Using #[inline] on the relvant functions in the http_parser example did not solve the
problem. LLVM/rustc does not seem to interpret that version of the attribute as a strong
indication that it should be inlined. Thankfully there is a stronger indication to the compiler
that it should inline: #[inline(always). Of course I immediately tried to liberally sprinkle
that attribute on all functions in examples/http_parser.rs and it turned out that this
actually just makes everything perform worse (kind of expexted, CPU-cache and all that).
Instead using #[inline(always)] on the exact same functions which were originally
automatically inlined by LLVM (without even needing the #[inline] attribute) produced the
best result for both approaches. Force-inlining request and request_line makes LLVM inline
in the same way for both variants. Now the performance gap is down to 5-10% only, and both are
faster than before by a small margin.
The code
The code can be found in the branch fifth here
and the specific commit tested was 128d7c70.
Results
Using the current beta (rustc 1.3.0-beta.3 (2a89bb6ba 2015-08-11), same as was used for the
previous performance test) and the same machine as in the previous tests (MacBook Pro retina
15-inch, late 2013 with 2.3 GHz Intel Core i7 and 16 GB RAM) we get the following numbers:
| Parser | Time, 21 kB | Time, 2 MB | Time, 204 MB |
|---|---|---|---|
| Simple | 0.003 s | 0.012 s | 0.948 s |
| Verbose | 0.003 s | 0.012 s | 0.974 s |
The major speedups seem to come from the following changes:
bindno longer backtracks on error; this avoids one extra branch-instruction in the most used construction in the whole library.- The internal
iter::Iterwas simplified a bit and there are 2 possible states instead of 3; this affected some of the combinators, making their matching code require fewer cases which hopefully optimizes better.
Overall I am pretty happy with the results, it is really starting to close in on the hand-written C-code listed above in the benchmark. And I hope that the tradeoffs I made are acceptable for the gain in parsing speed.
Now on to actually attempting to use this code in an application!
EDIT: Posted on Reddit here: /r/rust